
Disaster Recovery for DotCom
Disaster Recovery process contains playbooks for different components:
DotCom base infrastructure
Sourcegraph is deployed on Google Cloud Platform.
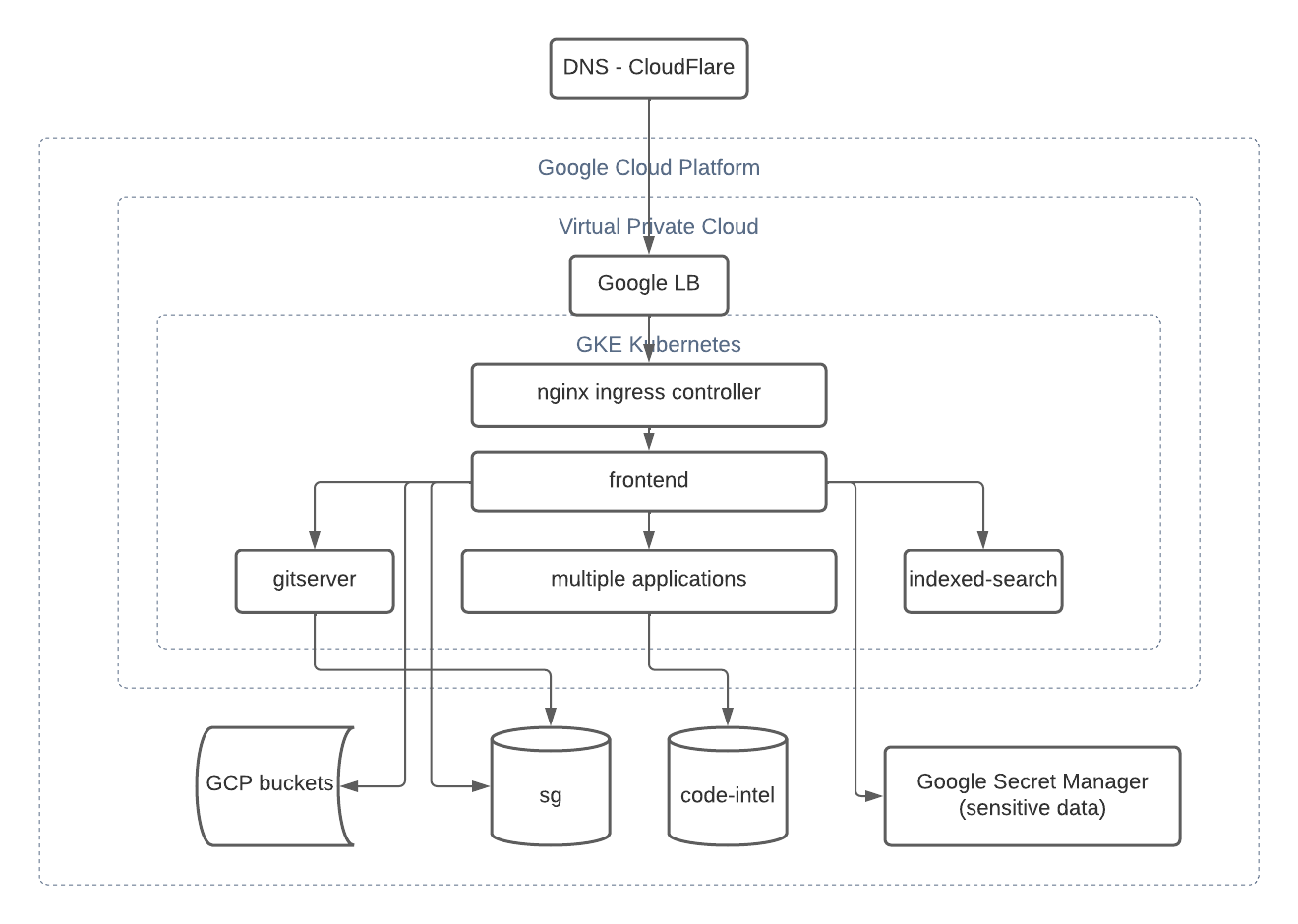
Before restoring all components from backups, terraform has to be applied to create:
- virtual private network with subnetworks
- CloudSQL instances with private VPC peering
- GKE Kubernetes cluster
- GCP service accounts
- Google Storage buckets
CloudSQL databases
Sourcegraph uses two Google CloudSQL instances:
Apart from automated daily backups, Sourcegraph performs database exports to Google Storage Bucket as recommended by Google.
Database backup process
Steps to create an export of the CloudSQL database into Google Storage bucket:
- Create Google bucket for exports:
gsutil mb -p sourcegraph-dev -l us gs://prod-database-export
- List SQL instances:
gcloud sql instances list
- Get service account for SQL instance:
gcloud sql instances describe <instance ID> | grep service
- Add database instance permission to create objects in the bucket:
gcloud projects add-iam-policy-binding sourcegraph-dev --member=serviceAccount:p323384348006-s6zx3o@gcp-sa-cloud-sql.iam.gserviceaccount.com --role=roles/storage.objectCreator
- Export the database into the bucket:
gcloud sql export sql --async --offload <instance ID> gs://prod-database-export/<instance ID>-$(date +%s).gz --database=sg
Meaning of the flags:
--async: return immediately, without waiting for the operation in progress to complete--offload: offload an export to a temporary instance. Doing so reduces strain on source instances and allows other operations to be performed while the export is in progress
- Check status of export, as with async flag, it returns immediately after invoking export command in previous point:
gcloud sql operations list --instance=<instance ID> --limit=10
Note: Export has to be in status: DONE
- Verify that the database dump was created:
gsutil ls gs://prod-database-export/
Database restore process
-
Create a CloudSQL database instance either via the terraform module
-
Create user:
gcloud sql users create sgdr --instance=<instance ID> --password=testdr
- Create database schema:
gcloud sql databases create sgdr --instance=<instance ID>
- Check available import files:
gsutil ls gs://prod-database-export/
- Import file from the bucket:
gcloud sql import sql <instance ID> gs://prod-database-export/<backup name>.gz --database=sgdr --user=sgdr
- Verify all tables are available:
- download SQLProxy
- start SQLProxy:
./cloud_sql_proxy -instances=sourcegraph-dev:us-central1:<instance ID>=tcp:0.0.0.0:5432
- connect to the database in another terminal tab:
psql "host=127.0.0.1 dbname=sgdr user=sgdr" (password: testdr)
- invoke commands in
psqlclient
\c sgdr
\dt
Note: last command should list all available tables in the sgdr database.
Google Secret Manager
All sensitive informations and files are kept and versioned in the Google Secret Manager. These secrets are then mounted to the applications deployed on the Google Cloud Kubernetes via terraform modules.
Google Secret Manager backup process
Steps to create backup of all existing secrets in Google Secret Manager:
- List all existing secrets:
SECRETS=$(gcloud secrets list | awk '!/NAME/ {print $1}')
- Iterate over secrets and make a copy of the latest version of the secret into the files:
for secret_name in $SECRETS; do
VERSIONS=$(gcloud secrets versions list $secret_name --limit 1 | awk '!/NAME/ {print $1}')
for secret_version in $VERSIONS; do
gcloud secrets versions access $secret_version --secret=$secret_name >$secret_name
done
done
Google Secret Manager restore process
Note: Restore process iterates over files in the folder and creates Google Manager Secrets from them.
Steps to restore Google Secret Manager secrets from files in the current folder:
for secret_name in *; do gcloud secrets create $secret_name --data-file=$secret_name; done
GKE Kubernetes
Google Kubernetes cluster is the platform for all applications. Applications are using ConfigMaps, Secrets and PersistentVolumes to keep their configuration, state and local cache.
Sourcegraph uses open source tool Velero to backup and restore GKE Kubernetes cluster state and GCP disk snapshots.
How to install Velero in GKE Kubernetes
Note: original documentation from Velero
- Set project:
gcloud config set project sourcegraph-dev
- Create bucket for cluster snapshot:
gsutil mb gs://sg-velero-prod-backup
- Export project ID:
PROJECT_ID=$(gcloud config get-value project)
- Create ServiceAccount for Velero:
gcloud iam service-accounts create velero --display-name "Velero service account"
- Export ServiceAccount email:
SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list --filter="displayName:Velero service account" --format 'value(email)')
- Export permissions required for GCP:
ROLE_PERMISSIONS=(
compute.disks.get
compute.disks.create
compute.disks.createSnapshot
compute.snapshots.get
compute.snapshots.create
compute.snapshots.useReadOnly
compute.snapshots.delete
compute.zones.get
)
- Create role for velero.server:
gcloud iam roles create velero.server \
--project $PROJECT_ID \
--title "Velero Server" \
--permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"
- Connect Velero ServiceAccount with Velero server role:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$SERVICE_ACCOUNT_EMAIL \
--role projects/$PROJECT_ID/roles/velero.server
- Add Velero ServiceAccount permissions to the snapshot bucket:
gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://sg-velero-prod-backup
- Create Velero ServiceAccount keys needed for installation on GKE Kubernetes:
gcloud iam service-accounts keys create credentials-velero --iam-account $SERVICE_ACCOUNT_EMAIL
- Install Velero on GKE Kubernetes:
velero install \
--provider gcp \
--plugins velero/velero-plugin-for-gcp:v1.4.0 \
--bucket sg-velero-prod-backup \
--secret-file ./credentials-velero \
--velero-pod-cpu-limit=1 \
--velero-pod-cpu-request=1 \
--velero-pod-mem-limit=512Mi \
--velero-pod-mem-request=512Mi \
--pod-annotations "cluster-autoscaler.kubernetes.io/safe-to-evict"="true"
- To prevent Velero from blocking cluster autoscaling, the pod should be deployed with a QoS of
Guaranteed. To achieve this, the initContainer needs to have its resources set as well, which cannot be done with CLI flags, so patch the deployment:
kubectl patch deploy velero -n velero --type json -p='[
{"op": "replace", "path": "/spec/template/spec/initContainers/0/resources/requests/memory", "value":"512Mi"},
{"op": "replace", "path": "/spec/template/spec/initContainers/0/resources/limits/memory", "value":"512Mi"},
{"op": "replace", "path": "/spec/template/spec/initContainers/0/resources/requests/cpu", "value":"1"},
{"op": "replace", "path": "/spec/template/spec/initContainers/0/resources/limits/cpu", "value":"1"}]'
Note: installation instructions for Velero cli
GKE Kubernetes backup process
GKE Kubernetes backup process is performed by Velero tool.
On demand backup steps
- Install Velero on GKE Kubernetes:
velero install \
--provider gcp \
--plugins velero/velero-plugin-for-gcp:v1.4.0 \
--bucket sg-velero-prod-backup \
--secret-file ./credentials-velero
- Invoke manual backup with disk snapshots:
velero backup create sgdr<timestamp> --snapshot-volumes --wait
Note: wait ensures the backup is done synchronously, so any error will be reported after it finishes.
- Verify backup is present and no errors:
velero backup get
- Verify disk snapshots are done:
gcloud compute snapshots list
Scheduled backup steps
- Install Velero on GKE Kubernetes:
velero install \
--provider gcp \
--plugins velero/velero-plugin-for-gcp:v1.4.0 \
--bucket sg-velero-prod-backup \
--secret-file ./credentials-velero
- Create scheduled backup with disk snapshots:
velero schedule create prod-daily --schedule="0 0 * * *" --snapshot-volumes=true
Note:
- daily schedules can be see by
velero schedule get - created backups can be seen by
velero backup get
GKE Kubernetes restore process
Important:
- new GKE Kubernetes cluster was created via terraform
- if Velero is going to restore a snapshot in a DIFFERENT GCP project, all steps from How to install velero in the GKE cluster have to be performed in the new GCP project.
- Connect to new GKE cluster:
gcloud container clusters get-credentials prod-dr --region us-central1 --project sourcegraph-dev
- Install Velero on GKE Kubernetes:
velero install \
--provider gcp \
--plugins velero/velero-plugin-for-gcp:v1.4.0 \
--bucket sg-velero-prod-backup \
--secret-file ./credentials-velero
- Add backup location to Velero (required if in previous step –bucket is not the same as the bucket used to make snapshot from origin cluster):
velero backup-location create prod-backups --provider gcp --access-mode=ReadOnly --bucket sg-velero-prod-backup
- Add disks snapshots location:
velero snapshot-location create prod-snapshots --provider gcp
- Check available backups and choose appropriate:
velero backup get
- Restore applications into new cluster (this will also create PV disks from GCP snapshots):
velero restore create prod-dr --from-backup sgdr<timestamp> --include-namespaces prod,ingress-nginx --wait
- Check if restore was successful:
velero restore describe prod-dr
Update nginx ingress controller
Note: if nginx ingress controller was also restored by Velero, please follow the steps to update it.
Fix nginx ingress controller after restore (only if restoring from running cluster):
- Remove Google LB IP from nginx configuration (cannot use a static IP that is already in use):
kubectl patch svc sg-nginx-ingress-nginx-controller --type=json -p="[{'op': 'remove', 'path': '/spec/loadBalancerIP'}]" -n ingress-nginx
- Login to original cluster and invoke (cluster roles are not restored by Velero):
kubectl get clusterroles sg-nginx-ingress-nginx -o yaml > cr_backup.yaml && kubectl get clusterrolebinding sg-nginx-ingress-nginx -o yaml > crb_backup.yaml
- Login to new cluster and invoke:
kubectl apply -f cr_backup.yaml && kubectl apply -f crb_backup.yaml
- Test Sourcegraph via public IP:
curl -ki https://$(kubectl get services -n ingress-nginx sg-nginx-ingress-nginx-controller --output jsonpath='{.status.loadBalancer.ingress[0].ip}')/search -H "Host: sourcegraph.com"
- Change CloudFlare to point to the new IP:
preview.sgdev.dev -> kubectl get services -n ingress-nginx sg-nginx-ingress-nginx-controller --output jsonpath='{.status.loadBalancer.ingress[0].ip}'
Deployments are stuck and Volumes won’t mount
In the event that the host machines on GKE change, and the nodes are having troubles mounting the volumes listed in the Sourcegraph.com deployment manifests. We can manually delete the Persistent Volume Claim, the deployment files associated and manually redeploy each service. The Volumes are set to retain so no data will be loss, it is just in the Kubernetes abstraction layer that the claim will be deleted from, the underlying storage will be kept in GCP. If services are failing to mount volumes, proceed with the following steps:
- Ensure Retain is set
- Run
kubectl delete pvc $target-pvc- This unblocks the deletion so it can proceed - Run
kubectl delete pod $podUsingThatPVC
Deletion occurs, PV and PVC gets deleted BUT the underlying disk is okay because of Retain.
The pod gets recreated but is blocked on startup because it can’t find the disk that fulfills requirement.
- Run
kustomize build base/$pod | kubectl apply -f -
Note: Check whether the deployment has kustomize options, if not it is sufficient to just run kubectl apply -f . in the directory of the desired service.
If you find that the deployment is not being rolled out, you can delete that deployment file first before re-applying.