
Sourcegraph monitoring architecture
This document describes the architecture of Sourcegraph’s monitoring stack, and the technical decisions we have made to date and why.
For development-related documentation, see the Sourcegraph monitoring guide and the observability developer documentation.
Long-term vision
To better understand our goals with Sourcegraph’s monitoring stack, please read monitoring pillars: long-term vision.
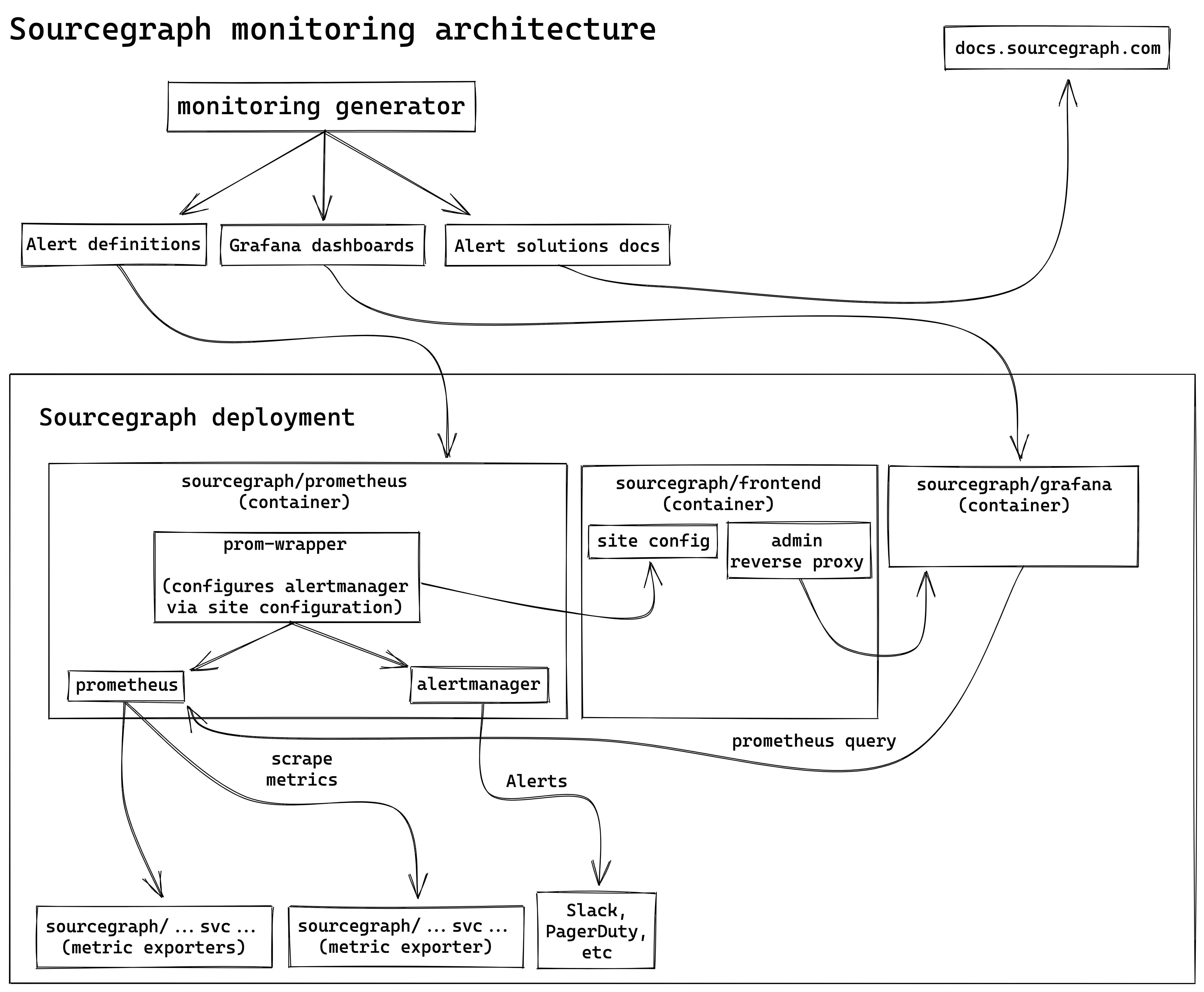
Monitoring generator
We use a custom declarative Go generator syntax for:
- Defining the services we monitor.
- Describing what those services do to site admins.
- Laying out dashboards in a uniform, consistent, and simple way.
- Generating the Prometheus alerting rules and Grafana dashboards.
- Generating documentation in the form of “possible solutions” for site admins to follow when alerts are firing.
This allows us to assert constraints and principles that we want to hold ourselves to, as described in our monitoring pillars, as well as provide integrations with our monitoring architecture.
To learn more about adding monitoring using the generator, see adding monitoring.
Standard Sourcgraph deployments
Sourcegraph Grafana
We use Grafana for:
- Displaying generated dashboards for our Prometheus metrics and alerts.
- Providing an interface to query Prometheus metrics and Jaeger traces.
The sourcegraph/grafana image handles shipping Grafana and Sourcegraph monitoring dashboards. It bundles:
- Preconfigured Grafana, which displays data from Prometheus and Jaeger
- Dashboards generated by the monitoring generator.
Admin reverse-proxy
For convenience, Grafana is served on /-/debug/grafana on all Sourcegraph deployments via a reverse-proxy restricted to admins.
Edits through the web UI are prohibited, for two reasons:
- We do not want customers, or ourselves, to introduce dashboards or modifications through the Grafana web UI (see monitoring pillars: long-term-vision)
- Services served via reverse-proxy in this manner could be vulnerable to cross-site request forgery (CSRF), which is complicated to resolve (#6075) without just forbidding all POST requests.
- The monitoring generator creates provisioned dashboards that, once loaded, cannot be edited in Grafana (technical limitation in Grafana.)
Sourcegraph Prometheus
We use Prometheus for:
- Collecting high-level, and low-cardinality, metrics from our services.
- Defining Sourcegraph alerts as both:
- Prometheus recording rules,
alert_count. - Prometheus alert rules (which trigger notifications) based on
alert_countmetrics.
- Prometheus recording rules,
The sourcegraph/prometheus image handles shipping Sourcegraph metrics and alerting. It bundles:
- Preconfigured Prometheus, which consumes metrics from Sourcegraph services.
- Alert and recording rules generated by the monitoring generator.
- Alertmanager, which handles alerts from Prometheus.
- prom-wrapper, which subscribes to updates in site configuration and propagates relevant settings to Alertmanager configuration.
Alert count metrics
alert_count metrics are special Prometheus recording rules that evaluate a single upper or lower bound, as defined in an Observable and generated by the monitoring generator. This metric is always either 0 if the threshold is not exceeded (or data does not exist, if configured), or 1 if the threshold is exceeded. This allows historical alert data to easily be consumed programmatically.
Learn more about the alert_count metrics in the metrics guide.
Rationale for alert_count: Why did we introduce alert_count metrics? At the time, a customer needed the ability to monitor their Sourcegraph instances’ health and we did not have any Prometheus metrics, alert definitions, or dashboards that they could consume. We knew that we would need to over time solidify our entire monitoring stack, which created a situation where in the interim we needed something that they could pipe to their own internal custom metrics and alerting system to monitor Sourcegraph health - without being tied to our exact Prometheus metrics, etc. such that we could continue to improve and refine them over the coming versions of Sourcegraph. To solve this, we introduced this alert_count metric which made it possible for them to query the firing alerts in Sourcegraph via the Prometheus API (we did not have alertmanager at the time either). There is some evidence that we may be able to use ALERTS instead of alert_count (tracking issue), but one problem there is that ALERTS does not show non-firing alerts and that has proven very useful both for this customer and to have in Grafana in general to instill some confidence that we are in fact monitoring a pretty substantial number of things. We believe alert_count can probably be replaced with ALERTS, but more discussion / a plan is needed.
Alert notifications
We use Alertmanager for:
- Providing data about currently active Sourcegraph alerts.
- Routing alerts to appropriate receivers and silencing them when desired, configured using site configuration.
Alertmanager is bundled in sourcegraph/prometheus, and notifications are configured for Sourcegraph alerts using site configuration. This functionality is provided by the prom-wrapper.
Rationale for notifiers in site configuration: Due to the limitations of admin reverse-proxies, alerts cannot be configured without port-forwarding or custom ConfigMaps, something we want to avoid.
Rationale for Alertmanager: An approach for notifiers using Grafana was considered, but had some issues outlined in #11832, so Alertmanager was selected as our notification provider.
Rationale for silencing in site configuration: Similar to the Grafana admin reverse-proxy, silencing using the Alertmanager UI would require port-forwarding, something we want to avoid.
prom-wrapper
The prom-wrapper is the entrypoint program for sourcegraph/prometheus and it:
- Handles starting up Prometheus and Alertmanager
- Applies updates to site configuration by generating a diff and applying changes
- Most notably, this includes configuring notifiers and silences for Sourcegraph alerts
- Exposes endpoints for configuration issues, alerts summary statuses, and reverse-proxies Prometheus and Alertmanager
Rationale for an all-in-one Prometheus image with prom-wrapper: This allows us to avoid adding a new separate service (which must be handled in all our deployment types), thus simplifying the deployment story for our monitoring stack, while also improving the alert debugging workflow (for example, simply port-forward svc/prometheus to get access to the entire alerting stack), with minimal disadvantages (for example, high-availability Prometheus and Alertmanager can still be configured via PROMETHEUS_ADDITIONAL_FLAGS and ALERTMANAGER_ADDITIONAL_FLAGS, and Alertmanager can be disabled via DISABLE_ALERTMANAGER).
Custom additions
To add custom dashboards for Cloud-specific needs, see Creating Cloud-only Grafana dashboards.
There is currently no process defining how custom alerts should be added. RFC 208 / #12396 is an ongoing discussion on what custom additions might look like.
Sourcegraph Cloud
Sourcegraph Cloud offers all the monitoring capabilities of a standard Sourcegraph deployment, as well as the following customizations and specific usages.
Alerts
Notifiers for alerts are configured via the deploy-sourcegraph-cloud frontend ConfigMap for site.json.
Alerts go to the #alerts channel, with critical alerts going to OpsGenie. Critical alerts are assigned responders in OpsGenie based on the owner field of each alert - the mapping of owner to engineering team can be found in the Sourcegraph Cloud site configuration.
Rationale for per-team alerts: See RFC 189 for an overview, and #12010 for the specifics of how and why this is implemented in Sourcegraph.
Blackbox Exporter
We use Blackbox Exporter for:
- Monitoring external and internal http endpoints
- Configuring alerts based on http response codes to notify teams when sourcegraph is unreachable via an external URL as well as
sourcegraph-frontend-internalto assist in diagnosing the root cause of sourcegraph being unavailable.
Prometheus scrapes Blackbox Exporter every 30s, which will send a request to endpoints configured via the deploy-sourcegraph-dotcom prometheus ConfigMap for prometheus.yaml.
Alerts are configured separately via the deploy-sourcegraph-dotcom prometheus ConfigMap for sourcegraph_dotcom_rules.yml
Rationale for Blackbox Exporter: Site24x7 has been a source of flaky alerts, outlined in #10742 and more broadly in #11966. In an effort increase reliablity and broaden the scope of our monitoring, Blackbox Exporter was selected as it integrates well into our existing Prometheus and Alertmanager stack.